言葉ってめんどくさい。色とか、気持ちで伝えればいいのに。
要点
- Sudachiのインストール
- Sudachi、なんかimportできない
- 形態素解析っぽいことをする
- 読みと品詞を取り出したい
前書き
形態素解析のお話です。
今までjanomeってやつを使っていました。こんな感じ。
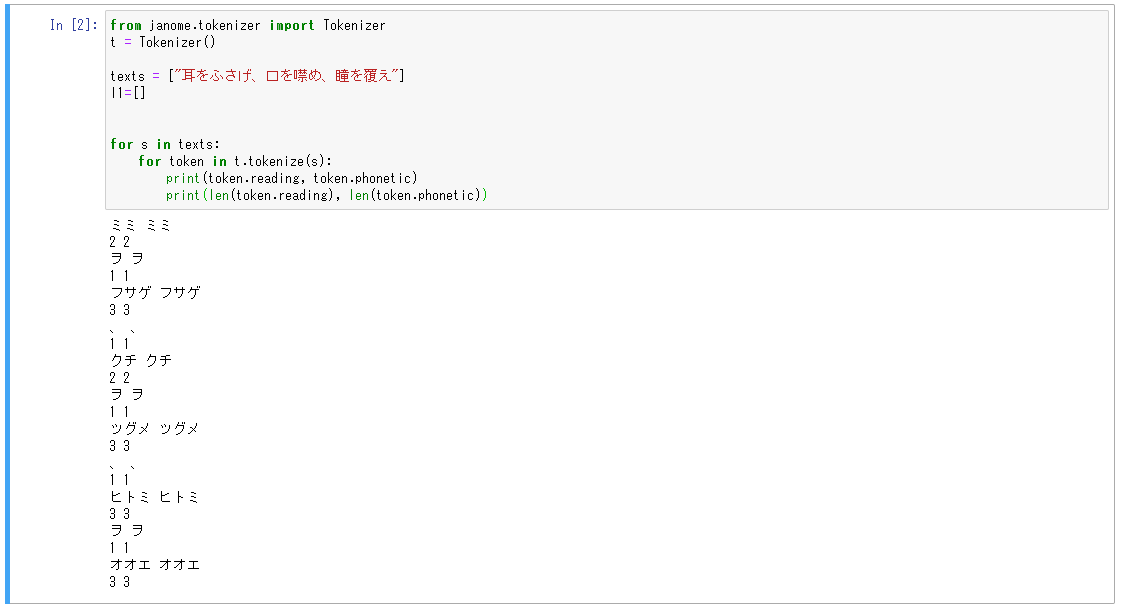
さて、問題が出ましてですね。
どうやらjanomeを使うと発音に「、」とか「。」とか「!」とかいう記号が出てきたりしてしまうっぽいんですのよ。それが嫌だなぁって思ったので対処法調べたけど見つからなかったのであきらめて別の形態素解析の何かを探すことにしようと思いました。その話を知人にすると「janomeメリットなくない?wowwow↑」って言われました。janomeに絶対的な信頼・・・を置いていたわけではないのですがまあMeCabでよいのでは?って気持ちを持っていたのでMeCabに触れてみようと思いました。
インストール
!pip install sudachipy !pip install sudachidict_core
pip install でインストールしました。
from sudachipy import tokenizer from sudachipy import dictionary tokenizer_obj = dictionary.Dictionary().create()
なんかエラー出た
ModuleNotFoundError
なんで?(殺意)
OSError: symbolic link privilege not held
モジュールが見つからないのかと思ったけどシンボリックリンクが作れないらしい。3秒考えて糸口が見つからないならGoogle先生に聞きましょう。
取り合えず、print文流し込んで何のシンボリックリンクを張ろうとしているか確認すると、
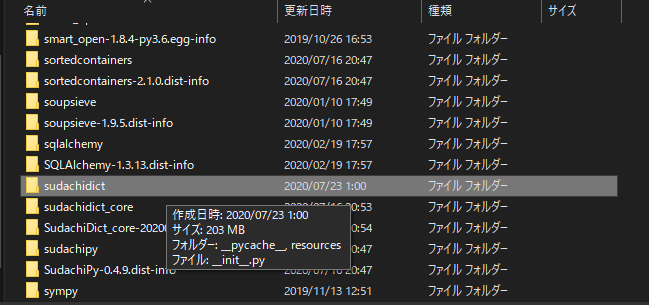
パッケージ内の「sudachidict_core」を「sudachidict」という別名にしたいらしい。
では、sudachidict_coreを丸々同じ場所にコピーしたsudachidictを作って、
先人様助かります。
Sudachiの辞書に3種類くらいあるからこうなっているんですかね?知らんけど。
追記:20220519
で、インストール終わっててきとーに
tokenizer_obj = dictionary.Dictionary().create()
とか呼ぶとModuleNotFoundErrorを吐くんだよねぇ~って思いながら再インストールしてましたが、

吐かないじゃん。
どうやらはかないこともあるようで。なんもわからん。バージョンの違いかも。2021年のバージョンぽかったので。
読みと品詞を取り出すコード
さて、今回作りたいのは文を入れたら形態素解析の辞書を返してくれるコード。
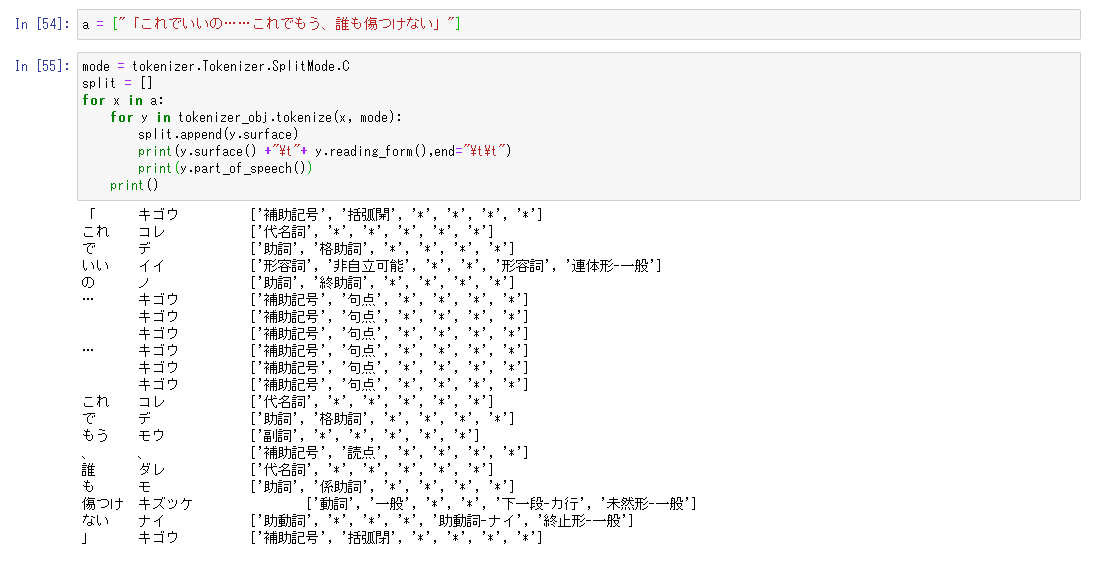
これを読まない記号の発音を消去して
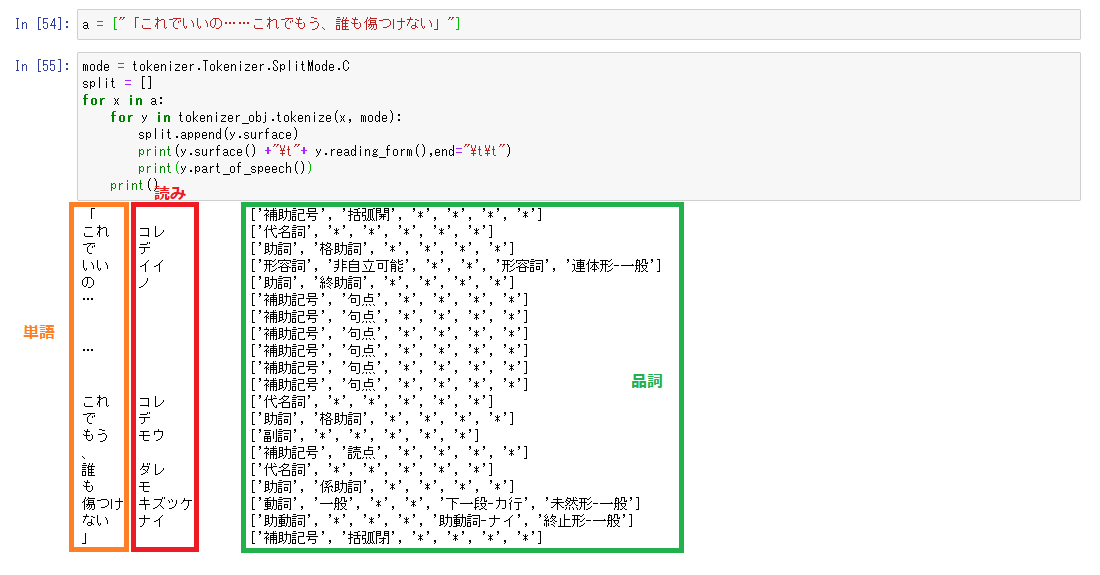
sen = [] for y in tokenizer_obj.tokenize(x, tokenizer.Tokenizer.SplitMode.C): dic = {} dic["A"] = y.surface() if y.part_of_speech()[0] != "補助記号": dic["pron"] = y.reading_form() else: dic["pron"] = "" dic["PoSp"] = y.part_of_speech() sen.append(dic)
絶対不具合起りそうなコードですね。
多分いつか手直ししそうな気がするんですけどまあいいでしょう。xに文を入れればsenに欲しいものが入って出てきます。
defで定義してないのは多分今後改造する気持ちがあるからでしてよ。
とりあえず今回はここまで
参考
Sudachi:GitHub
Sucachiのエラーの参考:https://www.optsp.co.jp/news/detail/2809/