事前に
偏差値3なので大昔、一番最初に読んだ本がマルコフ辞書って称してたのでマルコフ辞書って言い続けています。あんまりn-gramとの違いを理解しきっていない節があるので誰かが補足してくれたらありがたかったりします。誰がするんだろう。
考えたこと
- なんか問題あったら将来の私がブチギレながら直してくれるさ。
- 使うか分からないけれど文章辞書(SD)の保管
- もしかしたらランダムで単語辞書(WD)の品詞分類を基に単語を入れ替えるかもしれないので気持ちマルコフ辞書は細かくてもいいかも
- 同様の理由で、単語の出現率の記憶は保持しなくてもいいかも?←本当に?
- しれっとWDの1と2をBOS、EOSに変更した。これで生成の時、BOSとEOSが分かりやすくなる………はず。
- 検索を楽にやりたいから、マルコフ辞書(MD)の形を、キーをタプル、アイテムをリストにする
- それに伴い、新しくMDに追加するときはlen()=1のリストの形で入れる
忘れかけたこと
Q「SD/MDの数字ってなんだっけ?」
A「WDの単語番号です」
次回以降に回したこと
- 単語を入れ替える
- ユーザー辞書を作る・使う
→正直これしんどい
今回やること
- 辞書を作る
- 適当に生成してみる
辞書を作る
WD = {1:{'w': '<BOS>', 'pron': '', 'PoSp': ['BOS/EOS', '*', '*', '*', '*', 'BOS/EOS']},
2:{'w': '<EOS>', 'pron': '', 'PoSp': ['BOS/EOS', '*', '*', '*', '*', 'BOS/EOS']}} #単語辞書
SD = {} #文章辞書
MD = {} #マルコフ
texts = ["ロボットは人間に危害を加えてはならない。また、その危険を看過することによって、人間に危害を及ぼしてはならない。","ロボットは人間にあたえられた命令に服従しなければならない。ただし、あたえられた命令が、第一条に反する場合は、この限りでない。","ロボットは、前掲第一条および第二条に反するおそれのないかぎり、自己をまもらなければならない。"]
from sudachipy import tokenizer
from sudachipy import dictionary
tokenizer_obj = dictionary.Dictionary().create()
def tokenize(x):
sen = []
voidwordlist = ("補助記号","記号","空白")
dic = {"w":"<BOS>","pron":"","PoSp":["BOS/EOS", "*", '*', '*', '*', "BOS/EOS"]}
sen.append(dic)
for y in tokenizer_obj.tokenize(x, tokenizer.Tokenizer.SplitMode.C):
dic = {}
dic["w"] = y.surface()
if y.part_of_speech()[0] in voidwordlist:
dic["pron"] = ""
else:
dic["pron"] = y.reading_form()
dic["PoSp"] = y.part_of_speech()
sen.append(dic)
dic = {"w":"<EOS>","pron":"","PoSp":["BOS/EOS", "*", '*', '*', '*', "BOS/EOS"]}
sen.append(dic)
return sen
def RSearch(dic,q):
item = [k for k, v in dic.items() if v == q]
return item[0]
for text in texts:
sen = tokenize(text)
sd = []
for x in sen:
if x in WD.values():
ID = RSearch(WD,x)
else:
ID = len(WD)+1
WD[ID] = x
sd.append(ID)
SD[len(SD)+1] = sd
def MDAppend(k,i,MD):
if k in MD:
if i not in MD[k]:
MD[k].append(i)
else:
MD[k] = [i]
for x in SD:
s = SD[x]
if len(s) < 5:
pass
else:
m0 = s[0]
m1 = s[1]
m2 = s[2]
m3 = s[3]
m4 = s[4]
MDAppend((m0,m1,m2,m3),m4,MD)
for y in range(5,len(s)):
m0 = m1
m1 = m2
m2 = m3
m3 = m4
m4 = s[y]
MDAppend((m0,m1,m2,m3),m4,MD)
生成する
start = [] for x in MD.keys(): if 1 in x: start.append(x)
ここダサい。
import random start = random.choice(start) OT = list(start) w = 0 while w!= 2: w = random.choice(MD[tuple(OT[-4:])]) OT.append(w) output = "" for w in OT: output += WD[w]["w"] print(output)

じゃあ本格的にやってみよう
手元にたまたまあった、16140ツイートをまるっとぺろっと食わせました。
ただし、ツイートなので5単語より少ないものが存在します。見ての通りこれらは今の状態では餌になっていません。
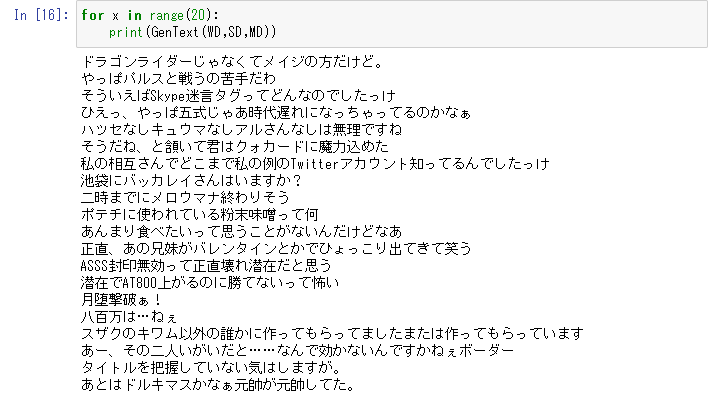
残念ながらそのままの発言っぽいものが多い。まあ予想通りというか当然なんだけれど。
- ドラゴンライダーじゃなくてメイジの方だけど。
→白猫の話。同一のツイートがあった。
- やっぱパルスと戦うの苦手だわ
→真空管ドールズの話。同一のツイートがあった。
- そういえばSkype迷言タグってどんなのでしたっけ
→同一のツイートがあった。
- ひえっ、やっぱ五式じゃあ時代遅れになっちゃってるのかなぁ
→黒ウィズ、魔道杯の話。魔道杯期間であり当時は六式が一番上か。同一のツイートがあった。
- ハツセなしキュウマなしアルさんなしは無理ですね
→黒ウィズ、魔道杯の話。上のツイートと似たような時期にツイートしている。
- そうだね、と頷いて君はクォカードに魔力込めた
→一時期流行っていたクォのQUOカード出たら面白いよねみたいな話題。同一のツイートがあった。
私の相互さんでどこまで私の例のTwitterアカウント知ってるんでしたっけ
→日本語が怪しいが、同一のツイートがあった。
- 池袋にバッカレイさんはいますか?
→どういう文脈か分からないが黒ウィズ、魔轟三鉄傑の話か。同一のツイートがあった。
- 二時までにメロウマナ終わりそう
→黒ウィズ、メロウを108匹集めていた話。同一のツイートがあった。
- ポテチに使われている粉末味噌って何
→粉末の味噌なんでしょう。同一のツイートがあった。
- あんまり食べたいって思うことがないんだけどなあ
→ものすごく自然な文章だが、同じツイートはない。
- 正直、あの兄妹がバレンタインとかでひょっこり出てきて笑う
→多分黒ウィズの話。どの兄妹なんでしょうか。ちょっとおかしいが同じツイートはない。
- ASSS封印無効って正直壊れ潜在だと思う
→黒ウィズの話。スペシャルスキルなのでSS封印と呼ぶ層がいたのを覚えていますか?同一のツイートがあった。
- 潜在でAT800上がるのに勝てないって怖い
→黒ウィズだがどの精霊の話か分からない。同一のツイートがあった。
- 月堕撃破ぁ!
→黒ウィズ、HereticBladerの話。同一のツイートがあった。
- 八百万は…ねぇ
→黒ウィズの話かと思ったが、同じツイートはなかった。
- スザクのキワム以外の誰かに作ってもらってましたまたは作ってもらっています
→同じツイートはなかった。別に異界転生したわけではないです。
- あー、その二人いがいだと……なんで効かないんですかねぇボーダー
→ちょっとおかしいが同じツイートはない。
- タイトルを把握していない気はしますが。
→同じツイートはなかった。タイトルくらい把握してほしいが。
- あとはドルキマスかなぁ元帥が元帥してた。
→黒ウィズの話。同一のツイートがあった。
まあ十分なんじゃないですかね、じゃあ単語入れ替えとかそこらへんは次回で。