長年pandasから逃げていましたが逃げられないことが多くなってきたので使うに応じて記憶の貯蔵をしていこうと決めました。
本当に何も分からないがそろそろpandasと和解していきたい。
未来の271108へ
matplotlibの時と同じように本当にメモ書きでつらつら書いていくのであとで清書してください。matplotlibの清書もやっておいてください。あれこの前更新したけど読みづらい、というかその場で必要になったことをその辺に落ちてたデータ使って無理やり記憶貯蔵しただけの記事なので。
まあ前書きはこんなのでいいでしょ。
- DataFrameを変換したい!
- 空のDataFrameを作りたい!
- DataFrameに行を追加していきたい!
- CSVで読み書きしたい!
- DataFrameの結合をしたい
- DataFrameをintに変換する
- 複数の列を表示したい
- 複数条件の検索
- 並び替えをしたい
- Seriesの値だけ取り出したい
- 行名・列名の検索をしたい
- 列名・行名を付けたい
- 列に格納されている値のバリエーションを確認したい
- 参考
DataFrameを変換したい!
List to DF
l_2d = [[0, 1, 2], [3, 4, 5]] df = pd.DataFrame(l_2d)
なお、行名列名を指定することも可能
df = pd.DataFrame(,
columns=["Col0", "Col1"],
index=["Ind0", "Ind1", "Ind2"]
DF to list
pandas.DataFrame, pandas.Seriesをリスト型に直接変換するメソッドは無いため、values属性で取得できるNumPy配列ndarrayを経由して、ndarrayのtolist()メソッドでリストに変換する。
df = pd.DataFrame([[0, 1, 2], [3, 4, 5]]) l_2d = df.values.tolist()
Dict to DF
普通にappendできるしそれじゃダメ?だめそうな処理するときになったら調べて。
たぶん参考になるはず。読んでないけど。
Python 辞書を Pandas DataFrame に変換する方法 | Delft スタック
DF to dict
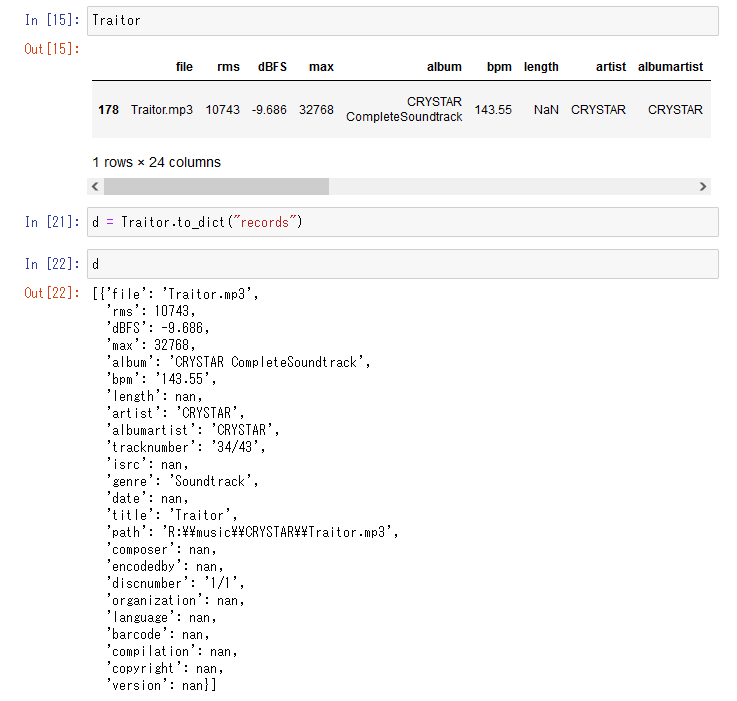
d = df.to_dict()
要調査
引数orientによって、pandas.DataFrameの行ラベル(行名)index、列ラベル(列名)columns、値valuesをどのように辞書のkey, valueに割り当てるかの形式を指定できる。
どういうことやねん
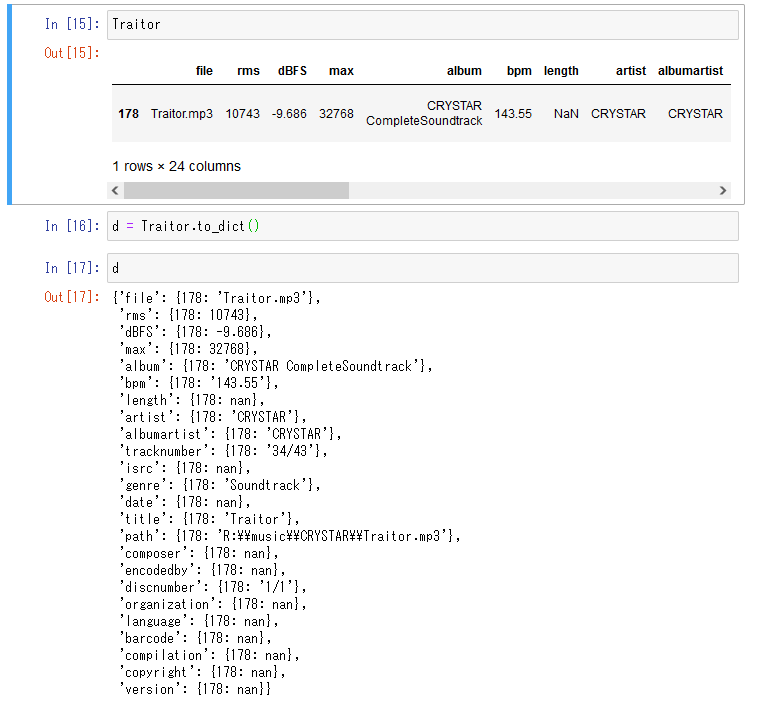
orientにはdict, list, series, split, records, indexの6種類が指定できる。
空のDataFrameを作りたい!
import pandas as pd df = pd.DataFrame(index=[], columns=cols)
DataFrameに行を追加していきたい!
気分としてはlistにappendしていきたい!みたいなものかね。
D2 = {}
D2["bpm"] = [compute_BPM(x)]
df = maindf.append(D2,ignore_index=True)
ignore_index=Trueにすることで、その列名が用意されていなくても新たに列を作って追加できる。
既存の列名がDataFrameにあるとその列に格納されるらしい。(というかまあ辞書型で入れてるから順番も何もないはずだしそりゃそうか)
CSVで読み書きしたい!
読み込み
df = pd.read_csv(csv_filename)
index_col を指定することでindexとなる列を指定できる。
一番左の列をindexにしたい場合はindex_col=0
書き込み
df.to_csv(csv_filename, header=True, index=True, encoding="utf-8_sig", sep=',')
header:headerをcsvに書くか(デフォルトTrue)
index:indexをcsvに書くか(デフォルトTrue)
encoding:出力ファイルのエンコーディング(デフォルトutf-8)
sep:csvの区切り文字(デフォルト,)
あとはmodeとかあったはず。
DataFrameの結合をしたい
下につけたい!
appendみたいな感じで追加したいんだけど、いっぱい追加したい!
df_v = pd.concat([df1, df2], axis=0)
axis=0の時は行が追加される。・・・って言っても私にはよく分からなかった。
雰囲気としては、df1の表の下にdf2の表がくっつくって感じ。
ぜんぜんわからない。俺たちは雰囲気でプログラミングをやっている
右につけたい!
右も左も変わらんのでは?私にぁ何のことかよく分かりましぇん。
df_h = pd.concat([df1, df2], axis=1)
要調査:join="outer" / ”inner”
DataFrameをintに変換する
df['A'] = df['A'].astype('int')
これをすると列Aだけintに変換できる。
複数の列を表示したい
a[["file","dBFS","rms","max"]]
こうする
複数条件の検索
df0_4 = maindf[(maindf["genre"] == "Soundtrack") | (maindf["genre"] == "東方")]
「|」や「&」を使ってできる
並び替えをしたい
df.sort_values(列名)
Seriesの値だけ取り出したい
df ["dBFS"].values.tolist()
index等々が消去されたリスト形式で出てくる。
行名・列名の検索をしたい
完全一致
df.filter(items=['完全一致させたいワード1', '完全一致させたいワード'])
部分一致
df.filter(like='count', axis=1)
指定した列以外のデータが欲しい
df[df.columns[df.columns != 'b']]
この場合要らない列はb
列名・行名を付けたい
df = pd.DataFrame(sr) colname = ["id", "author_name", "text"] df.columns = colname
列数と列名リストのサイズが違うと、エラーになる。
列に格納されている値のバリエーションを確認したい
v = df['where_get_from'].value_counts()
ユニークな要素の値がindex、その出現個数がdataになっているpd.Seriesが返ってくる。
参考
これそのまんまじゃん!って言われるかもしれないんですけど、Web上のものなんていつ消えるか・変わるかわかったものじゃないんです。私用の記憶貯蔵庫ですので後で私が困った時にこの記憶貯蔵庫見て、それでもわかんないなら参考元見直して、それでもわかんないならどうにかするために参考を書いているんです。
まあ、はてなブログが死んだらこれも消えるんですけどね。
pandas.pydata.org
qiita.com
https://note.nkmk.me/python-pandas-list/
https://note.nkmk.me/python-pandas-assign-append/
https://note.nkmk.me/python-pandas-to-csv/
https://note.nkmk.me/python-pandas-to-dict/
https://note.nkmk.me/python-pandas-read-csv-tsv/
https://note.nkmk.me/python-pandas-concat/
https://note.nkmk.me/python-pandas-dataframe-rename/
https://www.delftstack.com/ja/howto/python-pandas/how-to-add-one-row-to-pandas-dataframe/
https://www.delftstack.com/ja/howto/python-pandas/select-multiple-columns-pandas/
http://hxn.blog.jp/archives/11591404.html
https://linus-mk.hatenablog.com/entry/pandas_convert_float_to_int
https://qiita.com/tiger-for-fun/items/ab265c7e07141ff42805
https://note.nkmk.me/python-pandas-index-columns-select/