言葉ってめんどくさい。色とか、気持ちで伝えればいいのに。

この時点で思いつく問題点
- データベースどうやってつくるんだっけ?
- 未知の単語とかありそう。
とりあえず前回のメモを見つつ単語、読み、品詞にバラすものを作
from sudachipy import tokenizer from sudachipy import dictionary tokenizer_obj = dictionary.Dictionary().create() def tokenize(x): sen = [] voidwordlist = ("補助記号","記号","空白") dic = {"w":"<BOS>","pron":"","PoSp":["BOS/EOS", "*", '*', '*', '*', '*', "BOS/EOS"]} sen.append(dic) for y in tokenizer_obj.tokenize(x, tokenizer.Tokenizer.SplitMode.C): dic = {} dic["w"] = y.surface() if y.part_of_speech()[0] in voidwordlist: dic["pron"] = "" else: dic["pron"] = y.reading_form() dic["PoSp"] = y.part_of_speech() sen.append(dic) dic = {"w":"<EOS>","pron":"","PoSp":["BOS/EOS", "*", '*', '*', '*', '*', "BOS/EOS"]} sen.append(dic) return sen
った。
見覚えのあるコードだ・・・。
テスト1
固有名詞多いかな~って思ったけどそんなでもないかも。
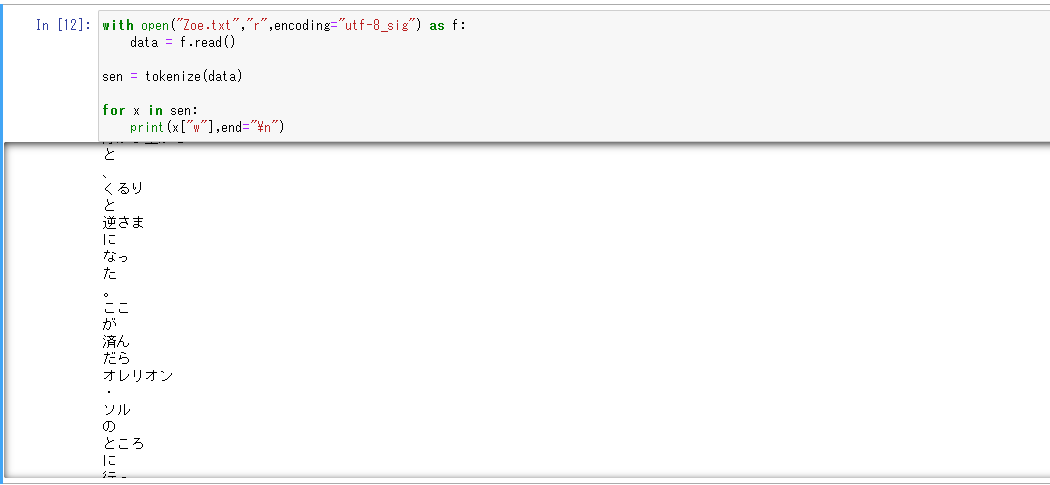
「オレリオン・ソル」が分かれてしまったがまあ問題ないような気もしないこともないような・・・?

って思ったけど品詞見たらダメでした。他にもパンテオン(人名)が地名扱いされているなど細かいものがちょこちょこ見つかった。
テスト2

こっちはまあ良さそう?
やること
ユーザー辞書登録
github.com
量が量なのでGUI作ってやったほうがいいかも?
んじゃ、次にデータベースをつくるやつやりますか。
参考資料
SQLとかいうものは記憶のどこかにあったようななかったような気がするので必要があれば記事に書くでしょう。
メモ
- ID被らないようにしたいけど既に読み品詞一致で登録されていればその番号で………ってする必要がある