音楽を結構よく聞くんですよ。
んで、その音楽、どうにもジャンルがバラバラ、音の大きさもバラバラ。Spotifyみたいなストリーミングサービスを使っているわけではないので仕方ないですが、正直微妙な気持ちになっています。
じゃあ解決したいよね。
0:前提条件
0-0:前置き
今回、調べても日本語記事が出てこないものが多くありました。私はとえいっくってテストで97点を取るくらい賢い*1です。ですが、間違っていることがあるかもしれません。間違ってたら指摘してくださいな。
5/5追記
あまりにも長くなりすぎてしんどくなってきました。というのも、2週間くらいでこれ完成させる気でいたのです。なので同じ記事で書けるかなぁって楽観視していたのですが、2ヵ月以上もかかってしまいました。これに関する記憶は貯蔵する価値がある気がしたのでどういうの作ろうかなぁとか考えてたものを含め貯蔵しようと思っています。ですが、長すぎる。いつものH2Use4Meとして使うときにも長すぎて邪魔になることでしょう。完成した時には記事分割します。
0-1:現環境
- 音声ファイルは既にある(mp3)
- ある程度の音量はそろっているが、全部がそうではない。
- 一部の未加工の音声ファイルは、序盤と終盤に空白がある。*2
0ー2:それを基にやりたいこと
1: 大まかでいいので音量を揃えたい。
そのために音量の振れ幅からはみ出ているものを見つける。
もしかしたら、歌詞がない音楽と歌詞がある音楽では同じ音量でも聞こえ方に差があるかもしれないのでその検証を行う。
2:最初と最後の無音区間の切り落としをしたい。
このために必要なのは無音と判定する閾値の大きさの選定。
それから無音区間を何秒まで許容するか。(0.2秒くらい?0.5秒くらいまでは許容できるかなぁ。)
3:現状、mp3ファイルに記録されているタグ情報を保持したい。
アーティスト名、タイトル、アルバム名、ジャンル……とかなんかある程度は管理していたはず。
1:メモ書き:pydub
はいこちらいつものメモ書きと同じような内容。
1ー0:インストール
FFmpegが必須らしい。一応必要なら↓から。
271108.hatenablog.com
それから普通にpythonでインストール。
pip install pydub
んでもって、FFmpeg内のexeファイルは全部アクセスできるようにしておくこと。(3敗)
FileNotFoundErrorだったかなんだかがでました。とりあえずアクセスが拒否されましたがまたも出ました。
1-1:ファイルの読み込み
import pydub from pydub import AudioSegment inputmp3 = r"Traitor.mp3" base_sound = AudioSegment.from_file(inputmp3, format="mp3") # base_sound = AudioSegment..from_mp3(inputmp3)
Tratior.mp3というファイルを読み込んだ例。
ところでformat="mp3"って指定してるってことはもしかして他の拡張子でも……?
www.ffmpeg.org
↑の拡張子はサポートしているらしい。(未検証)
from pydub import AudioSegment sound = AudioSegment.from_wav("test.wav")
と書いているものを見つけた。なんも分からん。
まあwavファイルも読み込むことはできるんでしょうね。
1-2:mp3の再生
import pydub from pydub import AudioSegment inputmp3 = r"Traitor.mp3" base_sound = AudioSegment.from_file(inputmp3, format="mp3") from pydub import playback playback.play(base_sound)
で再生できるはずだと思っていたが……
PermissionError: [Errno 13] Permission denied:
詳しいことは分からなかったが、simpleaudioをインストールすると解決するらしい。ホントか?
pip install simpleaudio
import pydub from pydub import AudioSegment inputmp3 = r"Traitor.mp3" base_sound = AudioSegment.from_file(inputmp3, format="mp3") from pydub import playback playback.play(base_sound)
流れた。ホントだった。疑ってすいません。
要調査
ところで
qiita.com
これについても調査したい。
import pyaudio from pydub import AudioSegment from pydub.utils import make_chunks audio_data = AudioSegment.from_mp3('./sample.mp3') p = pyaudio.PyAudio() stream = p.open(format=p.get_format_from_width(audio_data.sample_width), channels=audio_data.channels, rate=audio_data.frame_rate, output=True) for chunk in make_chunks(audio_data, 500): stream.write(chunk._data) stream.stop_stream() stream.close() p.terminate()
1-3:いろいろ確認
1-3-1:音量
print("RMS\t:{}\ndBFS\t:{:.3f}\nMax\t:{}".format(base_sound.rms,base_sound.dBFS,base_sound.max))
↑これは音量に関する確認。
RMS:英語にするとRoot Mean Square value。人間の聴覚特性に準じていない。
dBFS:FSは「フルスケール」の事で、通常は負の値を取る。
Max:多分一番音が大きいとき。Peakと同じかな?
1-3-2:音声の長さ
#音声の長さ base_sound.duration_seconds
単位は秒。
1-3-3:フレームレート
#音声のフレームレート base_sound.frame_rate
1-4:音声の加工
1-4-1:切り出し・結合
# base_sound = 音声データが入っている変数 first_five_second = base_sound[:5*1000] last_ten_second = base_sound[10*1000:] # 元の音声の最初と最後を結合 concated_sound = first_five_second + last_ten_second
pydubの単位がミリ秒なのでfirst_five_secondは最初の5秒分の音データを格納している。
音声データの結合は + でいいらしい。これは元の音声の最初と最後を結合らしい。
1-4-2:音量
# base_sound = 音声データが入っている変数 from pydub.utils import db_to_float, ratio_to_db loud_sound = base_sound + 6 # 音量を6dbだけ上げる quiet_sound = base_sound - 10 # 音量を10db下げる ratio = 0.8 # 0.8倍の音量にしたい quiet_sound2 = base_sound + ratio_to_db(ratio)
1-4-3:無音区間の切り落とし
chunks = split_on_silence(base_sound , min_silence_len=2000, silence_thresh=-40, keep_silence=500) # 分割したデータ毎にファイルに出力 for i, chunk in enumerate(chunks): chunk.export("output" + str(i) +".wav", format="wav")
どうやらfor文で回すならこうやらないといけないらしい。
それはそれとして、
min_silence_len=2000 2000ms以上無音なら分割
silence_thresh=-40 -40dBFS以下で無音と判定
keep_silence=500 分割後500msは無音を残す
の意味になるらしい。
1-5:音声ファイルの保存
# base_sound = 音声データが入っている変数 # outputmp3 = 出力ファイルのパス base_sound.export(outputmp3, format="mp3")
なお、引数bitrateを用いてビットレートの指定を行わないと、可変ビットレートで出力される。この際、VBR Headerが用意されないため例えばiTunesのような一部のソフトウェアで読み込んだ際に再生時間などの表示に異常が発生する。
1-6:無音区間を調べる
from pydub.silence import detect_silence inputmp3 = r"Traitor.mp3" base_sound = AudioSegment.from_file(inputmp3, format="mp3") chunks = detect_silence(base_sound, min_silence_len=500, silence_thresh=-40)
min_silence_len:最小無音区間の長さ(単位はミリ秒)
silence_thresh:dFBSでの無音判定を行う際の閾値
なお、逆にdetect_nonsilent()という無音区間でない区間を調べる関数もある。
1-7:先頭の無音区間の終了時間を調べる
from pydub.silence import detect_leading_silence inputmp3 = r"Traitor.mp3" base_sound = AudioSegment.from_file(inputmp3, format="mp3") chunks = detect_leading_silence(base_sound, silence_threshold=-40)
先頭の無音が終了するミリ秒を調べる。
CouldntDecodeError: Decoding failed. ffmpeg returned error code: 1
発生したエラー。基本的には「mp3ファイルをwavファイルとして読み込んだ」とかそういうのに対して出るエラーっぽい。
今回これが発生したときはその音楽ファイルが壊れていたためこのエラーが起きた。このエラーに苦しんだのならば正しい拡張子でそのファイルを開こうとしているか、そしてそのファイルが壊れてないか確認すればいいんじゃないですかね。
2:メモ書き:mutagen
2-0:インストール
pip install mutagen
2-1:EasyID3
2-1-1:読み込み
inputmp3 = r"Traitor.mp3"
tag = EasyID3(inputmp3)
このtagとかいうやつ、辞書型みたいな形で返ってくる。
tag.keys()とかtag.values()とか実行できた。
{'album': ['CRYSTAR CompleteSoundtrack'], 'artist': ['CRYSTAR'], 'albumartist': ['CRYSTAR'], 'discnumber': ['1/1'], 'tracknumber': ['34/43'], 'genre': ['Soundtrack']}こんな感じ。
2-1-2:タグ書き込み
inputmp3 = r"Traitor.mp3" tag = EasyID3(inputmp3) tag['title'] = 'Aristoteles' tag.save()
こうすると、タイトルがAristotelesになる。
tags = EasyID3(inputmp3)
print(tags.pprint())
album=CRYSTAR CompleteSoundtrack albumartist=CRYSTAR artist=CRYSTAR discnumber=1/1 genre=Soundtrack title=Aristoteles tracknumber=34/43
なるほどと。
2-1-3:タグ一覧
EasyID3.valid_keys.keys()
でどんなタグがあるのか確認できる。
一応全部書くか。赤いやつは設定する。青いやつはやる気があったら設定する。
でもって、残りも現状のファイルにそのデータがあるならそれに応じて対応することを考えておきましょう。うん。
album:アルバム
bpm:BPM(まあ自動計算できるしやるか。)
compilation:この音楽ファイルがコンピレーションアルバムのファイルであるかを示す?ここを1にするとコンピレーション扱いになる。
composer:作曲者
copyright:コピーライト
encodedby:エンコード方式?
lyricist:作詞者
length:長さ
media:
mood:
title:タイトル
version:バージョン
artist:アーティスト
albumartist:アルバムアーティスト(※私の場合だとiPhoneの都合上アーティストと同じ)
conductor:指揮者
arranger:アレンジした人(これ設定する?)
discnumber:ディスクナンバー
organization:組織
tracknumber:トラックナンバー
author:著者(これは・・・?)
albumartistsort:アルバムアーティスト(読み方)
albumsort:アルバム(読み方)
composersort:作曲者(読み方)
artistsort:アーティスト(読み方)
titlesort:タイトル(読み方)
isrc:
discsubtitle:ディスクの副題
language:言語
genre:ジャンル
date:日付
originaldate:
performer:*:
musicbrainz_trackid:
website:ウェブサイト
replaygain_*_gain:
replaygain_*_peak:
musicbrainz_artistid:
musicbrainz_albumid:
musicbrainz_albumartistid:
musicbrainz_trmid:
musicip_puid:
musicip_fingerprint:
musicbrainz_albumstatus:
musicbrainz_albumtype:
releasecountry:
musicbrainz_discid:
asin:
performer:
barcode:
catalognumber:
musicbrainz_releasetrackid:
musicbrainz_releasegroupid:
musicbrainz_workid:
acoustid_fingerprint:
acoustid_id:
2-2:mutagen.id3(いつか書くかも)
もっといろいろいじれるらしい。が、そこまでする気力が今は多分ない。
KeyError: 'TPE1'
KeyError: 'TPE1'
というエラーが出た。例えば["artist"]が登録されていないにもかかわらず、それを呼んだ時に出るKeyErrorっぽい。違うかもしれないが。5分位これで悩んでいたので一応貯蔵しておく。
未確認
mutagenを使ってこれを変更できるかもしれない。可変ビットレートのヘッダー情報を書き換えられるかもしれない。とりあえず今回は使わなかったけど調べたら出てきたので一応残しておく。
https://mutagen.readthedocs.io/en/latest/api/mp3.html
3:実践編
3-1:基準の音量はどのくらい?
3-1-1:Try1
そもそも音量ってどのくらいなの?ってなる。
普段聞いてる曲(51曲)はどれもうるさいとも聞きにくいとも思ったことがないので、それを前提に考える。(もっとも、そのために過去に編集した可能性が極めて高い。)
これらを基に、基準の音量の定義をしていきたい。
とりあえずヒストグラムかなんかを作って全体の形を把握。
%matplotlib inline import matplotlib.pyplot as plt import pydub from pydub import AudioSegment from pydub.utils import db_to_float, ratio_to_db from pydub.silence import split_on_silence import pandas as pd import os from tqdm.notebook import tqdm def extension_list(path,extension): import os def FileList(path): files = [] D = os.listdir(path) for d in D: path2 = path + "\\"+ d if os.path.isfile(path2): files.append(path2) elif os.path.isdir(path2): f = FileList(path2) files.extend(f) return files fl = FileList(path) R = [] for file in fl: root, ext = os.path.splitext(file) if ext == r"." + extension: R.append(file) return R path = r"E:\Main" mp3FileList_Main = extension_list(path,extension="mp3") L = [] for x in mp3FileList_Main: base_sound = AudioSegment.from_file(x, format="mp3") L.append([os.path.basename(x),base_sound.rms,round(base_sound.dBFS,3),base_sound.max]) maindf = pd.DataFrame(L,columns = ["file","rms","dBFS","max"]) path = r"E:\music" mp3FileList_ALL = extension_list(path,extension="mp3") L2 = [] for x in mp3FileList_ALL: try: base_sound = AudioSegment.from_file(x, format="mp3") L2.append([os.path.basename(x),base_sound.rms,round(base_sound.dBFS,3),base_sound.max]) except Exception as e: if os.path.basename(x).endswith(".mp3") print("エラー:{}".format(os.path.basename(x))) print(e) else: pass alldf = pd.DataFrame(L2,columns = ["file","rms","dBFS","max"]) edges = range(4000,16000,1000) fig, ax = plt.subplots(2, 2, figsize=(12, 12)) ax[0,0].hist(maindf["rms"],ec='black',bins=edges) ax[0,0].set_title("Main_RMS") ax[0,0].grid(True) ax[1,0].hist(alldf["rms"],ec='black',bins=edges) ax[1,0].set_title("ALL_RMS") ax[1,0].grid(True) edges = range(-20,3,2) ax[0,1].hist(maindf["dBFS"],ec='black',bins=edges) ax[0,1].set_title("Main_dBFS") ax[0,1].grid(True) ax[1,1].hist(alldf["dBFS"],ec='black',bins=edges) ax[1,1].set_title("ALL_dBFS") ax[1,1].grid(True) plt.show()
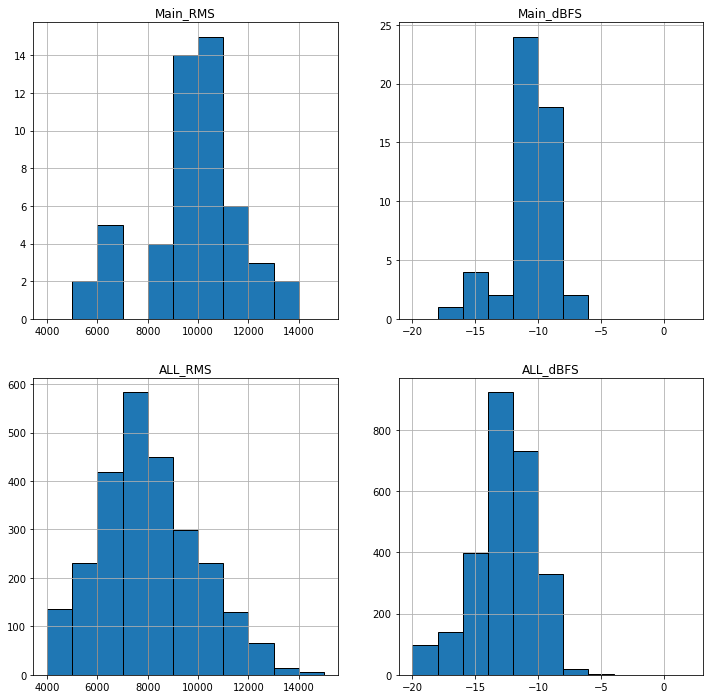
Mainがよく聞いている音楽、ALLが音楽フォルダ全体。
どうやら、普段聞いてる曲に比べて全体でみると音量が小さいかもしれない。
rmsは8000~12000が無難か?
dBFSの基準としていい感じなのは-14~-6dBと考えてもいいかもしれない。
そこから外れているものを確認する。
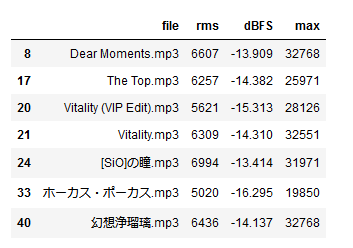
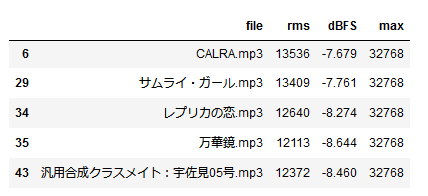
まあ予想通りではあったが、ここで出てくるファイルはだいたい同じよね。
……って待った。
Vitality (VIP Edit).mp3
Vitality.mp3
幻想浄瑠璃.mp3
これら全部サウンドトラックにあたるものだからもしかしたら聞こえ方が違うのかもしれない。んでもって、音楽ファイル全部でやった時、黒ウィズ、の他にも、ATRI、CRYSTAR、DDLC、Helltaker、LC/LoR、NGODをはじめとした、あまりにも多いサウンドトラックがあったはず。ファイル数で比較したことはないけれど、歌唱があるものよりも多くなっていてもおかしくない。
さらに、これやろうと思い立ったきっかけもNGODのサントラが気持ち音大きく感じたから。聞こえ方に違いがあるかの確認をするために、ジャンルがサウンドトラックになっているものは別にしてヒストグラムを描き直した方がいいはず。
3-1-2:Try2「ジャンルごとに分けてみて見ましょう」
といっても、よく聞く区分にしている音楽は51曲。歌詞がないものは5曲しかない……はず。目で確認したから違うかもだけど。
じゃあ、タグのgenreがSoundtrackまたは東方でないもので分ければいい……はず。自信なくなってきたな。ちゃんと管理していた気がしないよ。
はいじゃあ確認!……と行きたいところだけれど、ここから作業するにはあまりにもやらなきゃいけないことが多い。
これらは多分後で使うから、全部まとめてやっておいちゃいましょう。
%matplotlib inline import matplotlib.pyplot as plt import pydub from pydub import AudioSegment from pydub.utils import db_to_float, ratio_to_db from pydub.silence import split_on_silence from pydub import playback import pandas as pd import numpy as np import os from tqdm.notebook import tqdm from mutagen.easyid3 import EasyID3 import librosa import pickle def extension_list(path,extension): import os def FileList(path): files = [] D = os.listdir(path) for d in D: path2 = path + "\\"+ d if os.path.isfile(path2): files.append(path2) elif os.path.isdir(path2): f = FileList(path2) files.extend(f) return files fl = FileList(path) R = [] for file in fl: root, ext = os.path.splitext(file) if ext == r"." + extension: R.append(file) return R def compute_BPM(music): ly, sr = librosa.load(music) onset_env = librosa.onset.onset_strength(ly, sr=sr) tempo = librosa.beat.tempo(onset_envelope=onset_env, sr=sr) if len(tempo)==1: return round(tempo[0],2) else: print(music,tempo) path = r"E:\Main" mp3FileList_Main = extension_list(path,extension="mp3") maindf = pd.DataFrame(index=[],columns = ["file","rms","dBFS","max"]) for x in mp3FileList_Main: base_sound = AudioSegment.from_file(x, format="mp3") D1 = {"file" : os.path.basename(x), "rms" : base_sound.rms, "dBFS" : round(base_sound.dBFS,3), "max" : base_sound.max} D2 = EasyID3(x) D2["bpm"] = [compute_BPM(x)] DC = dict(D1, **D2) maindf = maindf.append(DC,ignore_index=True) path = r"E:\music" mp3FileList_ALL = extension_list(path,extension="mp3") alldf = pd.DataFrame(index=[],columns = ["file","rms","dBFS","max"]) for x in mp3FileList_ALL: try: base_sound = AudioSegment.from_file(x, format="mp3") D1 = {"file" : os.path.basename(x), "rms" : base_sound.rms, "dBFS" : round(base_sound.dBFS,3), "max" : base_sound.max} D2 = EasyID3(x) D2["bpm"] = [compute_BPM(x)] DC = dict(D1, **D2) alldf = alldf.append(DC,ignore_index=True) except Exception as e: if os.path.basename(x).endswith(".mp3") print("エラー:{}".format(os.path.basename(x))) print(e) else: pass
わあ長い。これで得られたalldfとmaindfが基本的に使うやつです。
が、うまくいかなかったのでこれは没に。
3-1-3:Try3「うまくいきませんでした。」
pickleがうまく使えなかったのでDataFrameじゃなくて辞書を格納したリスト形式で一旦pickleで書き出して*3、それを読み込んで処理かな。
で、最終的にやらせたのがこれ↓
%matplotlib inline import matplotlib.pyplot as plt import pydub from pydub import AudioSegment from pydub.utils import db_to_float, ratio_to_db from pydub.silence import split_on_silence from pydub import playback import pandas as pd import numpy as np import os from tqdm.notebook import tqdm from mutagen.easyid3 import EasyID3 import librosa import pickle def extension_list(path,extension): import os def FileList(path): files = [] D = os.listdir(path) for d in D: path2 = path + "\\"+ d if os.path.isfile(path2): files.append(path2) elif os.path.isdir(path2): f = FileList(path2) files.extend(f) return files fl = FileList(path) R = [] for file in fl: root, ext = os.path.splitext(file) if ext == r"." + extension: R.append(file) return R def compute_BPM(music): ly, sr = librosa.load(music) onset_env = librosa.onset.onset_strength(ly, sr=sr) tempo = librosa.beat.tempo(onset_envelope=onset_env, sr=sr) if len(tempo)==1: return round(tempo[0],2) else: print(music,tempo) path = r"R:\Main" mp3FileList_Main = extension_list(path,extension="mp3") with open("mp3FileList_Main.pickle", "wb") as f: pickle.dump(mp3FileList_Main, f) #maindf = pd.DataFrame(index=[],columns = ["file","rms","dBFS","max"]) mainL = [] for x in mp3FileList_Main: base_sound = AudioSegment.from_file(x, format="mp3") D1 = {"file" : os.path.basename(x), "rms" : base_sound.rms, "dBFS" : round(base_sound.dBFS,3), "max" : base_sound.max} D2 = EasyID3(x) D2["bpm"] = [compute_BPM(x)] DC = dict(D1, **D2) mainL.append(DC) #maindf = maindf.append(DC,ignore_index=True) with open("mainL.pickle", "wb") as f: pickle.dump(mainL, f) path = r"R:\music" mp3FileList_ALL = extension_list(path,extension="mp3") path = r"R:\music" mp3FileList_ALL = extension_list(path,extension="mp3") #alldf = pd.DataFrame(index=[],columns = ["file","rms","dBFS","max"]) allL = [] for x in mp3FileList_ALL: try: base_sound = AudioSegment.from_file(x, format="mp3") D1 = {"file" : os.path.basename(x), "rms" : base_sound.rms, "dBFS" : round(base_sound.dBFS,3), "max" : base_sound.max} D2 = EasyID3(x) D2["bpm"] = [compute_BPM(x)] DC = dict(D1, **D2) #alldf = alldf.append(DC,ignore_index=True) allL.append(DC) except Exception as e: if os.path.basename(x).endswith(".mp3"): print("エラー:{}".format(os.path.basename(x))) print(e) else: pass with open("allL.pickle", "wb") as f: pickle.dump(allL, f) with open("mp3FileList_ALL.pickle", "wb") as f: pickle.dump(mp3FileList_ALL, f)
次にやるのはSoundTrack系統とその他の曲で差があるかどうかの確認だったのに、もはや先にタグの処理をしないとどうしようもない状態に。まあ結局いつかやる羽目になっていたのでいいでしょう。。
といっても、51曲の方で確認するだけだと足りない気がするのでそこをどうするかを考える前に面倒なことになってしまった。。
と同時に、まあ残念ながら、タグまでしっかり回収する羽目になったのでしたのでタグの処理も考えちゃいましょうしなければなりません。。
t = mainL t[18]["album"] t[18] type(t[18]["album"])
ってやって、1つとりあげて情報を確認すると、
{'album': ['CRYSTAR CompleteSoundtrack'],
'albumartist': ['CRYSTAR'],
'artist': ['CRYSTAR'],
'bpm': ['143.55'],
'dBFS': -9.71,
'discnumber': ['1/1'],
'file': 'Traitor.mp3',
'genre': ['Soundtrack'],
'max': 32768,
'rms': 10714,
'tracknumber': ['34/43']}で、typeはlist。BPMが文字列なのがちょっとばかし気に食わないけれどまあいいでしょうよ。
で、タグがむちゃくちゃになっているので厄介者をあぶりだすために処理をした。
with open("mainL.pickle","rb") as f: mainL = pickle.load(f) with open("allL.pickle","rb") as f: allL = pickle.load(f) with open("mp3FileList_Main.pickle","rb") as f: mp3FileList_Main = pickle.load(f) with open("mp3FileList_All.pickle","rb") as f: mp3FileList_All = pickle.load(f) def mp3FileTagList_Molding(L,mp3FileList): #L:mainL/allLを入れる #mp3FileList:mp3FileList_Mainやmp3FileList_Allを入れる L2 = [] EL = [] if len(L) == len(mp3FileList): for i in range(len(L)): flag = False d = L[i] for tag in d.keys(): #print(tag) if type(d[tag]) == list: if len(d[tag]) == 1: d[tag] = d[tag][0] else: #print(i,tag) flag = True else: d[tag] = d[tag] d["path"] = mp3FileList[i] #print(d) if flag: #print() EL.append(i) L2.append(d) return L2,EL else: print("Error") return False mainML, EL_m = mp3FileTagList_Molding(mainL, mp3FileList_Main) allML, EL_a = mp3FileTagList_Molding(allL , mp3FileList_All)
で、ちょいとばかし手作業。問題が起きているファイルはどれかを調べた。
普段聞いてる曲では問題が起きてなかったので良し。全ファイルの方もしんどかったけどまあなんとかした。
boc = [94, 95, 97, 100, 101, 102, 105, 110, 113, 125, 126, 127, 128, 130, 137] lea = [255, 256, 257, 258, 259, 260, 261, 262, 263, 264, 265, 266, 267, 268, 269, 270, 271, 272, 273, 274, 275, 276, 277, 278] for e in boc: d = allML[e] path = d["path"] filename = os.path.basename(path) root, ext = os.path.splitext(filename) #print(root) d["title"] = root if type(d["album"]) == list: if len(d["album"])>1: d.pop("album", None) allML[e] = d for e in lea: d = allML[e] if type(d["title"]) == list: if len(d["title"])>1: d["title"] = d["title"][1] if type(d["album"]) == list: if len(d["album"])>1: d["album"] = d["album"][1] allML[e] = d
↑これいる?
boc、leaはそれぞれ問題児のファイルリスト。まあ雑に処理できるものでよかった。これだけじゃ、全部解決はしてないけどね。
……はい、これでようやくジャンルごとの処理ができるでしょう。ようやくか。
と思っていた時期が私にもありました。>
まあ処置しておきましょう。
d = mainML[4] d.pop("genre") mainML[4] = d maindf = pd.DataFrame(mainML) alldf = pd.DataFrame(allML) df0 = maindf[(maindf["genre"] == "Soundtrack") | (maindf["genre"] == "東方")] DF0 = maindf[(maindf["genre"] != "Soundtrack") & (maindf["genre"] != "東方")] df1 = alldf[(alldf["genre"] == "Soundtrack") | (alldf["genre"] == "東方")] DF1 = alldf[(alldf["genre"] != "Soundtrack") & (alldf["genre"] != "東方")] edges = range(4000,16000,1000) fig, ax = plt.subplots(2, 2, figsize=(12, 12)) fig.set_facecolor('w') ax[0,0].hist(df0["rms"],ec='black',bins=edges, color = "r", alpha=0.3) ax[0,0].hist(DF0["rms"],ec='black',bins=edges, color = "b", alpha=0.3) ax[0,0].set_title("Main_RMS") ax[0,0].grid(True) ax[1,0].hist(df1["rms"],ec='black',bins=edges, color = "r", alpha=0.3) ax[1,0].hist(DF1["rms"],ec='black',bins=edges, color = "b", alpha=0.3) ax[1,0].set_title("ALL_RMS") ax[1,0].grid(True) edges = range(-20,3,2) ax[0,1].hist(df0["dBFS"],ec='black',bins=edges, color = "r", alpha=0.3) ax[0,1].hist(DF0["dBFS"],ec='black',bins=edges, color = "b", alpha=0.3) ax[0,1].set_title("Main_dBFS") ax[0,1].grid(True) ax[1,1].hist(df1["dBFS"],ec='black',bins=edges, color = "r", alpha=0.3) ax[1,1].hist(DF1["dBFS"],ec='black',bins=edges, color = "b", alpha=0.3) ax[1,1].set_title("ALL_dBFS") ax[1,1].grid(True) plt.show()
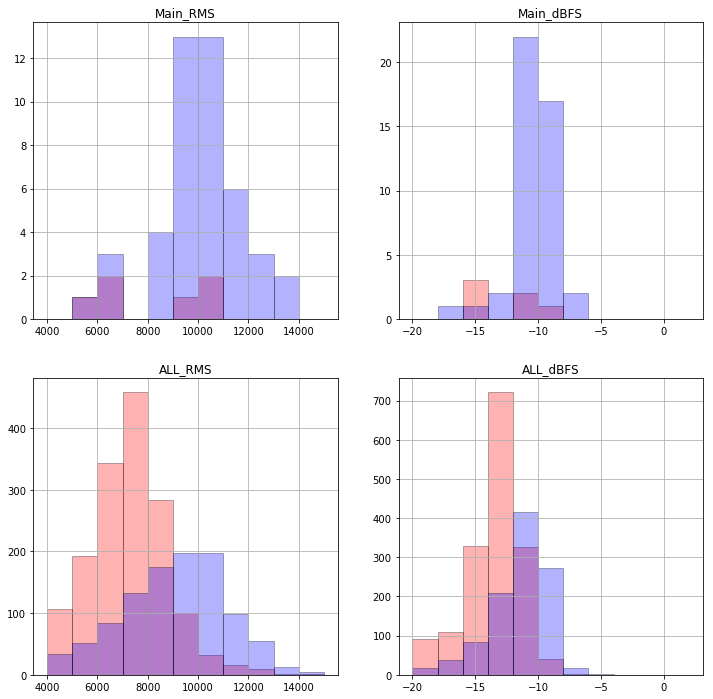
なるほどなんも分からん。
3-1ー4「空白部分を除去したもので再確認しよう」
空白部分を除去しました。
具体的には
def Lead_and_Last_drop(base_sound): silence_threshold = -40 reverse_sound = base_sound.reverse() length = base_sound.duration_seconds * 1000 lead = detect_leading_silence(base_sound, silence_threshold=silence_threshold) last = detect_leading_silence(reverse_sound, silence_threshold=silence_threshold) processedAudio = base_sound[lead:length-last] return processedAudio
って関数を作って、
path = r"R:\Main" mp3FileList_Main = extension_list(path,extension="mp3") mainL = [] for x in mp3FileList_Main: base_sound = AudioSegment.from_file(x, format="mp3") base_sound = Lead_and_Last_drop(base_sound) D1 = {"file" : os.path.basename(x), "rms" : base_sound.rms, "dBFS" : round(base_sound.dBFS,3), "max" : base_sound.max, "length":base_sound.duration_seconds} D2 = EasyID3(x) D2["bpm"] = [compute_BPM(x)] DC = dict(D1, **D2) mainL.append(DC) with open("mp3FileList_Main.pickle", "wb") as f: pickle.dump(mp3FileList_Main, f) with open("mainL.pickle", "wb") as f: pickle.dump(mainL, f) mainML, EL_m = mp3FileTagList_Molding(mainL, mp3FileList_Main) with open("mainML.pickle", "wb") as f: pickle.dump(mainML, f)
って感じで、もうそもそも最初に表作るところからやり直しました。多分そのはず。
さぞかし成果があるんでしょう。
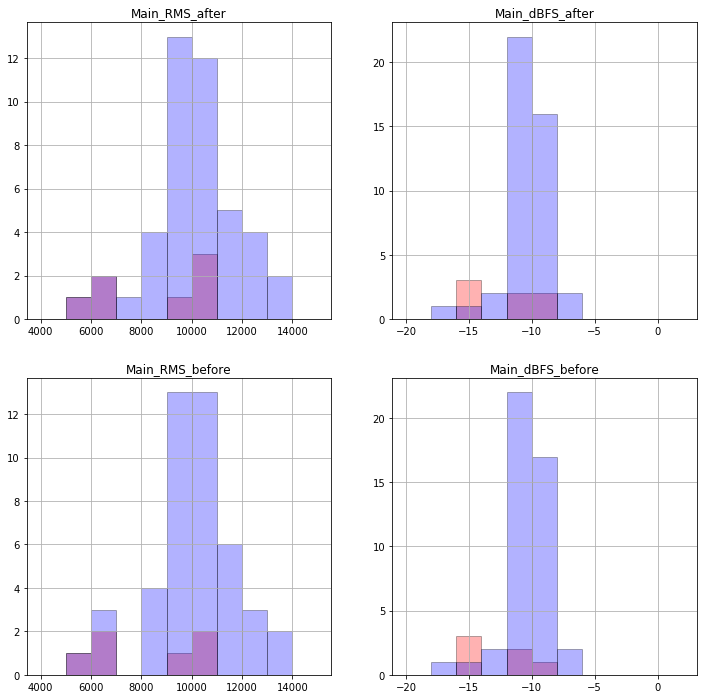
ほっとんどかわんないじゃん!!!
キレそう
何も分からん。
検討案
音が小さいの定義(Soundtrack以外)
max != 32768 かつ dBFS <= -12.5?
3-2:結局。
普段聞いている曲の中で一番うるさそうだった曲を基準としました。もちろん、サウンドトラックも普段から聞くので同様の処理をします。
同様に、この曲が一番音小さいなって思った曲を下限としました。
3-2-1:構想
- 特定のファイルに変換したいファイルを置いておく
- この時、サウンドトラックのフォルダとそうでないフォルダは分けておく
- この時には、ある程度のタグは登録しておく
- 音量を変換「特定の曲を上限下限にする」
- 同時にタグも変換
- アーティストごとにフォルダ分けしてmusicフォルダに保存
3-2-2
っていうことで実際にファイルを全部まとめて処理をしたい。
同時に、ファイル分類もやってくれないかな……。
あとあと、同じサウンドトラックの時の音量調整は均一になるようにしないといけないよね……。
……ってことはよく考えると、今のファイルは極力いじらないほうがいいんじゃないか?
今のファイルに対してはとりあえずタグ情報の書き込みをしましょう。
バックアップを取ったので、一斉に書きかえをするコードを書きましたと。ついでに前後の空白を落とすのも同時にやってもらいましょうか。
ということで多分コードはこう。
with open("3-2-2_allML.pickle","rb") as f: allML = pickle.load(f) def tag_rewrite(file, d): tags = EasyID3(file) for t in EasyID3.valid_keys.keys(): tag_now = d.get(t) if tag_now: if type(tag_now) == float or type(tag_now) ==int: if math.isnan(tag_now): continue else: tags[t] = tag_now else: tags[t] = tag_now else: continue tags.save() for row in allML: file = row["path"] base_sound = AudioSegment.from_file(file, format="mp3") base_sound = Lead_and_Last_drop(base_sound) base_sound.export(file, format="mp3") tag_rewrite(file, row)
このブログ記事だけではallMLって何だっけ?ってなるので一応
3-2-3:ファイル分け?
多分ファイル分けをするべき。で、問題はどういう階層を取らせるべきかが4/28時点で決まっていないのでそれを考える。
- アーティストごとにすると、主にボカロ系にある例えば鳴花ヒメと鳴花ミコトで歌ってるような複数アーティストの曲を割り振るうえで問題が発生しそう。
- ジャンルも複数ジャンルある曲もあったはず。
- 正直今のファイル階層は結構ぐちゃぐちゃなので参考にはならない。
- ジャンルごとにすると、例えば黒ウィズのサントラのように「SoundTrack」と歌唱の入っているジャンル未設定曲*4が別々のフォルダになって管理が厄介かもしれない。
- 全ファイル同一フォルダ内保管という暴挙もあるけど……やりたくはないわなぁ。ファイル数3159って書いてあるし。
アーティストごと、複数アーティストの時はアーティスト名順に並び替えて何らかの文字でつないだフォルダにする。
- アーティスト名を取得
- もしかしたら「 . \ / : * ? " < > | 」の文字がアーティスト名に使われているかもしれないのでその処理をする。文字の置き換えをする。
- アーティスト名が複数あった時、「何らかの文字」でつないでフォルダ名を生成
- ディレクトリが存在してなければ作る
- 「音楽ファイルの加工をする」
作ったもの
import pydub from pydub import AudioSegment from pydub.utils import db_to_float, ratio_to_db from pydub.silence import split_on_silence,detect_leading_silence from pydub import playback import pandas as pd import numpy as np import os from mutagen.easyid3 import EasyID3 import librosa import pickle import math import tarfile import datetime import shutil from tqdm import tqdm def extension_list(path,extension): import os def FileList(path): files = [] D = os.listdir(path) for d in D: path2 = path + "\\"+ d if os.path.isfile(path2): files.append(path2) elif os.path.isdir(path2): f = FileList(path2) files.extend(f) return files fl = FileList(path) R = [] for file in fl: root, ext = os.path.splitext(file) if ext == r"." + extension: R.append(file) return R def compute_BPM(music): ly, sr = librosa.load(music) onset_env = librosa.onset.onset_strength(ly, sr=sr) tempo = librosa.beat.tempo(onset_envelope=onset_env, sr=sr) if len(tempo)==1: return round(tempo[0],2) else: print(music,tempo) def Lead_and_Last_drop(base_sound): silence_threshold = -40 reverse_sound = base_sound.reverse() length = base_sound.duration_seconds * 1000 lead = detect_leading_silence(base_sound, silence_threshold=silence_threshold) last = detect_leading_silence(reverse_sound, silence_threshold=silence_threshold) processedAudio = base_sound[lead:length-last] return processedAudio def tag_rewrite(file, d): tags = EasyID3(file) for t in EasyID3.valid_keys.keys(): tag_now = d.get(t) if tag_now: if type(tag_now) == float or type(tag_now) ==int: if math.isnan(tag_now): continue else: tags[t] = tag_now else: tags[t] = tag_now else: continue tags.save() def artists_dir_create(artist): if len(artist) > 0: for a in artist: a.replace(r"." , "") a.replace("\\" , "") a.replace(r"/ ", "") a.replace(r":" , "") a.replace(r"*" , "") a.replace(r"?" , "") a.replace(r'"' , "") a.replace(r"<" , "") a.replace(r">" , "") a.replace(r"|" , "") a.replace(r" " , "") a.replace(r" " , "") if len(artist) == 1: directory = r"R:\music\{}".format(artist[0]) if os.path.exists(directory): return directory else: os.mkdir(directory) return directory elif len(artist) > 1: artist = sorted(artist) artist_name_str = "" for a in artist[:-1]: artist_name_str+=a artist_name_str+="_" artist_name_str+=artist[-1] directory = r"R:\music\_VA\{}".format(artist_name_str) if os.path.exists(directory): return directory else: os.makedirs(directory) return directory else: directory = r"R:\music\_不明" if os.path.exists(directory): return directory else: os.mkdir(directory) return directory import warnings warnings.simplefilter('ignore') okiba = r"music_exe" #cwd = os.getcwd() +"\\" + okiba filelist = extension_list(path=okiba,extension="mp3") with open("Thresholds.pickle","rb") as f: Thresholds = pickle.load(f) c = 0 errorlist = [] for x in tqdm(filelist): c = c+1 #ファイルを読み込むフェーズ try: base_sound = AudioSegment.from_file(x, format="mp3") base_sound = Lead_and_Last_drop(base_sound) D1 = {"file" : os.path.basename(x), "dBFS" : round(base_sound.dBFS,3), "max" : base_sound.max} D2 = EasyID3(x) D2["bpm"] = [compute_BPM(x)] if "artist" in D2.keys(): D2["albumartist"] = D2["artist"] if "title" not in D2.keys(): filename = os.path.basename(x) root, ext = os.path.splitext(filename) D2["title"] = root except Exception as e: errorlist.append([x,e,"i"]) continue #音量をいじるフェーズ try: if Thresholds[1] <= D1["dBFS"] <= Thresholds[0]: volume_changed_sound = base_sound elif D1["dBFS"] < Thresholds[1]: #小さすぎる volume_changed_sound = base_sound + round(Thresholds[1] - D1["dBFS"] ,3) elif D1["dBFS"] > Thresholds[0]: #大きすぎる volume_changed_sound = base_sound - round(D1["dBFS"] - Thresholds[0] ,3) else: errorlist.append([x,r"{},{},{}".format(Thresholds[1],D1["dBFS"],Thresholds[0]),"c"]) continue except Exception as e: errorlist.append([x,e,"c"]) continue #出力フェーズ try: directory = artists_dir_create(D2["artist"]) outputmp3 = directory + "\\" + D1["file"] volume_changed_sound.export(outputmp3, format="mp3") D_tmp = EasyID3(outputmp3) for t in D2.keys(): D_tmp[t] = D2[t] D_tmp.save() except Exception as e: errorlist.append([x,e,"o"]) continue if len(errorlist) == 0: now = datetime.datetime.now() nowtext = "{:0=4}-{:0=2}-{:0=2}-{:0=2}-{:0=2}".format(now.year,now.month,now.day,now.hour,now.minute) tarpath = r"R:\music_tar\{}.tar.gz".format(nowtext) with tarfile.open(tarpath, 'w:gz') as tr: tr.add(okiba) shutil.rmtree(okiba) os.makedirs(okiba, exist_ok=True) else: for x in errorlist: print(x)
3-2-4:新しい問題:可変ビットレート
さあ編集できた曲を確認しようと思いましたがiTunesに叩き込むと表示されている時間がおかしい。実際に再生してみると、問題はないものの表示だけがおかしい。これは過去に別件であったことなのですが、可変ビットレート(VBR)とかいうもののによるものだったはずです。
んで、調べると、mutagenを使ってこれを変更できるかもしれない。
https://mutagen.readthedocs.io/en/latest/api/mp3.html
考えられる手としては2つ。
volume_changed_sound.export(outputmp3, format="mp3")
↓
volume_changed_sound.export(outputmp3, format="mp3", bitrate=元ファイルのビットレート)
- 上記の通り、mutagenを使ってこれを変更できるかもしれない。
可変ビットレートにこだわってないし、と言うか元々固定ビットレートだったし、上でいいか。
で、折角なのでそのままiTunesに叩き込んじゃいましょう。
#!/usr/bin/env python # coding: utf-8 import pydub from pydub import AudioSegment from pydub.utils import db_to_float, ratio_to_db from pydub.silence import split_on_silence,detect_leading_silence from pydub import playback import pandas as pd import numpy as np import os from mutagen.easyid3 import EasyID3 from mutagen.mp3 import MP3 import librosa import pickle import math import tarfile import datetime import shutil from tqdm import tqdm def extension_list(path,extension): import os def FileList(path): files = [] D = os.listdir(path) for d in D: path2 = path + "\\"+ d if os.path.isfile(path2): files.append(path2) elif os.path.isdir(path2): f = FileList(path2) files.extend(f) return files fl = FileList(path) R = [] for file in fl: root, ext = os.path.splitext(file) if ext == r"." + extension: R.append(file) return R def compute_BPM(music): ly, sr = librosa.load(music) onset_env = librosa.onset.onset_strength(ly, sr=sr) tempo = librosa.beat.tempo(onset_envelope=onset_env, sr=sr) if len(tempo)==1: return round(tempo[0],2) else: print(music,tempo) def Lead_and_Last_drop(base_sound): silence_threshold = -40 reverse_sound = base_sound.reverse() length = base_sound.duration_seconds * 1000 lead = detect_leading_silence(base_sound, silence_threshold=silence_threshold) last = detect_leading_silence(reverse_sound, silence_threshold=silence_threshold) processedAudio = base_sound[lead:length-last] return processedAudio def tag_rewrite(file, d): tags = EasyID3(file) for t in EasyID3.valid_keys.keys(): tag_now = d.get(t) if tag_now: if type(tag_now) == float or type(tag_now) ==int: if math.isnan(tag_now): continue else: tags[t] = tag_now else: tags[t] = tag_now else: continue tags.save() def artists_dir_create(artist): if len(artist) > 0: for a in artist: a.replace(r"." , "") a.replace("\\" , "") a.replace(r"/ ", "") a.replace(r":" , "") a.replace(r"*" , "") a.replace(r"?" , "") a.replace(r'"' , "") a.replace(r"<" , "") a.replace(r">" , "") a.replace(r"|" , "") if len(artist) == 1: directory = r"R:\music\iTunesに自動的に追加\{}".format(artist[0]) if os.path.exists(directory): return directory else: os.mkdir(directory) return directory elif len(artist) > 1: artist = sorted(artist) artist_name_str = "" for a in artist[:-1]: artist_name_str+=a artist_name_str+="_" artist_name_str+=artist[-1] directory = r"R:\music\iTunesに自動的に追加\_VA\{}".format(artist_name_str) if os.path.exists(directory): return directory else: os.makedirs(directory) return directory else: directory = r"R:\music\iTunesに自動的に追加\_不明" if os.path.exists(directory): return directory else: os.mkdir(directory) return directory import warnings warnings.simplefilter('ignore') okiba = r"music_exe" #cwd = os.getcwd() +"\\" + okiba filelist = extension_list(path=okiba,extension="mp3") with open("Thresholds.pickle","rb") as f: Thresholds = pickle.load(f) c = 0 errorlist = [] for x in tqdm(filelist): c = c+1 #ファイルを読み込むフェーズ try: base_sound = AudioSegment.from_file(x, format="mp3") base_sound = Lead_and_Last_drop(base_sound) D1 = {"file" : os.path.basename(x), "dBFS" : round(base_sound.dBFS,3), "max" : base_sound.max} D2 = EasyID3(x) D2["bpm"] = [compute_BPM(x)] audio = MP3(x) bitrate = audio.info.bitrate if "artist" in D2.keys(): D2["albumartist"] = D2["artist"] if "title" not in D2.keys(): filename = os.path.basename(x) root, ext = os.path.splitext(filename) D2["title"] = root except Exception as e: errorlist.append([x,e,"i"]) continue #音量をいじるフェーズ try: if Thresholds[1] <= D1["dBFS"] <= Thresholds[0]: volume_changed_sound = base_sound elif D1["dBFS"] < Thresholds[1]: #小さすぎる volume_changed_sound = base_sound + round(Thresholds[1] - D1["dBFS"] ,3) elif D1["dBFS"] > Thresholds[0]: #大きすぎる volume_changed_sound = base_sound - round(D1["dBFS"] - Thresholds[0] ,3) else: errorlist.append([x,r"{},{},{}".format(Thresholds[1],D1["dBFS"],Thresholds[0]),"c"]) continue except Exception as e: errorlist.append([x,e,"c"]) continue #出力フェーズ try: directory = artists_dir_create(D2["artist"]) outputmp3 = directory + "\\" + D1["file"] volume_changed_sound.export(outputmp3, format="mp3", bitrate=bitrate) D_tmp = EasyID3(outputmp3) for t in D2.keys(): D_tmp[t] = D2[t] D_tmp.save() except Exception as e: errorlist.append([x,e,"o"]) continue if len(errorlist) == 0: now = datetime.datetime.now() nowtext = "{:0=4}-{:0=2}-{:0=2}-{:0=2}-{:0=2}".format(now.year,now.month,now.day,now.hour,now.minute) tarpath = r"R:\music_tar\{}.tar.gz".format(nowtext) with tarfile.open(tarpath, 'w:gz') as tr: tr.add(okiba) shutil.rmtree(okiba) os.makedirs(okiba, exist_ok=True) else: for x in errorlist: print(x)
(2022/5/6時点)
欲しいもの
- mp4をmp3に変換する
- 現状のwebmをmp3に変換するやつを拡張子指定してへんな処理しないように保護
- タイトル・アーティスト名その他を入力する入力フォームが欲しい
考えること
3-2-3
あとあと、同じサウンドトラックの時の音量調整は均一になるようにしないといけないよね……。
メモ
— @271108_ (@271108_) 2022年5月3日
同一スケールで変換するなら、全ファイルに対してLead_and_Last_dropをかけて、全部くっつけて、そのあと音量比較して、その比較情報を基にして変換すればいいのでは?
↑これいる?
Compilations判定が出るタグがもしかして存在している?後で確認しておく
KeyError('TPE1',)
NotADirectoryError(20, 'ディレクトリ名が無効です。')
*** どうやって差があるか確認する?(3-1-2)
次にやるのはSoundTrack系統とその他の曲で差があるかどうかの確認。
といっても、51曲の方で確認するだけだと足りない気がするのでそこをどうするかを考える。
聞いている感じ、大きく差がないと思うんだよねぇ……。
案1:もう少しSoundTrack系統でよく聞く音楽をピックアップして検証?
他の案は?
タグ問題
- 文字化けしているものがある気がするけど大丈夫?
→ある程度処置した。まだ残っているので一覧で見てまだ処理しなきゃいけないはず。
- lengthに変なものが入っているものがある。
最終的なタグの形をこう定義する
album:1文字列
albumartist:artistと同じ
artist:複数にする余地を残す
bpm:1数値
date:年月日まで(それより詳しい情報を落とす。現状ないが、日付型にはまらないものを確認)
genre:複数にする余地を残す……?
isrc:ほとんどで使われていないしよく分からないが温存
length:1数値(単位を決めていないので決めること)
tracknumber:未定(某ゲームの曲に「1/Yesod」とか「2/Da'at」とか書いてあるのセンスを感じるがはっ倒してやろうかという気持ちにもなる。これやったの私じゃね?)
title:1文字列に最終的にはしたい。文字化けの温床。
composer:文字化けの温床2。複数の方が都合がいいと思う。
discnumber:「n/m」の形でいいかな……?
encodedby:変更しなくていい
organization:全角スペースを使うな
language:いらない。現状1曲にしか入ってないし不要。
barcode:いらない。これも別の1曲にしか入ってないし不要。
compilation:0と1しか入ってないし、まあ残しといてもいいかな……
copyright:正直残したいが、文字化けやら表記ゆれやらがひどい。人間は自然言語を使うな。という気持ちになる。
version:残しておいていい。多分これ私がつけたやつしかない。
参考
順番に特に規則がないです。
https://qiita.com/nyancook/items/786cffd0b07bad8b4444
https://qiita.com/ekzemplaro/items/a9bddad00dcf461de98a
https://wpchiraura.xyz/python_how-to-solve-when-permissionerror-errno-13/
https://self-development.info/pydub%E3%81%AB%E3%82%88%E3%82%8Awav%E3%82%92mp3%E3%81%AB%E5%A4%89%E6%8F%9B%E3%81%99%E3%82%8B%E3%80%90python%E3%80%91/
https://techacademy.jp/magazine/39369
https://oto-to-mimi.com/mixing/about-peak-and-rms/
https://soundevotee.net/blog/2017/03/04/which_rms_value_are_you_refering/
https://www.g200kg.com/jp/docs/dic/dbfs.html
https://algorithm.joho.info/programming/python/pydub-split-on-silence/
https://qiita.com/TakuTaku36/items/91032625e482f2ae6e18
https://note.nkmk.me/python-mutagen-mp3-id3/
https://www.wizard-notes.com/entry/music-analysis/compute-bpm
https://www.wizard-notes.com/entry/music-analysis/compute-bpm-with-librosa
https://qiita.com/__Attsun__/items/e033d689c336315435b3
https://www.audiolabs-erlangen.de/resources/MIR/2017-GI-Tutorial-Musik/2017_MuellerWeissBalke_GI_BeatTracking.pdf
https://qiita.com/tiger-for-fun/items/3faff2ac40885ab59a5f
https://qiita.com/sotetsuk/items/80c57896735aee4b0306
https://github.com/jiaaro/pydub
https://mutagen.readthedocs.io/en/latest/api/mp3.html
https://algorithm.joho.info/programming/python/pydub-bitrate-format/
https://stackoverflow.com/questions/17777198/what-is-the-tpe1-keyerror
http://blog.livedoor.jp/poizen/archives/57690060.html